
João de Deus

Bruno Teixeira
Our AI-generated summary
Our AI-generated summary
Porque o escalonamento é mais complexo do que parece
O escalonamento da produção é um dos problemas de otimização mais comuns no contexto industrial. Quando bem executado, pode gerar melhorias tangíveis no desempenho do negócio, como níveis de serviço mais elevados ou maior eficiência das máquinas através da redução de tempos de setup. No entanto, resolver estes problemas está longe de ser trivial.
Na indústria do papel, em particular, o problema de escalonamento das linhas de transformação — onde grandes bobines de papel são convertidas nas folhas utilizadas no dia a dia — é extremamente complexo. Envolve múltiplas máquinas, múltiplos SKUs e múltiplas decisões interdependentes. O desafio agrava-se devido a limitações industriais práticas que impõem tempos máximos de execução aos algoritmos de otimização.
O caso real aqui apresentado envolve o sequenciamento de mais de 100 ordens em 6 máquinas ao longo de uma semana, num dos maiores fabricantes mundiais de papel. Os planos de produção estavam ainda sujeitos a um conjunto de restrições operacionais e de planeamento típicas, como dependências de stock provenientes de máquinas anteriores, disponibilidade das máquinas e tempos de setup dependentes da sequência entre ordens. Tudo isto enquanto se procurava equilibrar níveis de stock, níveis de serviço e eficiência das máquinas.
Os limites da otimização clássica
Neste contexto, por otimização clássica entende-se a formulação matemática do problema como um modelo MILP (Mixed-Integer Linear Programming), resolvido por um solver que melhora iterativamente a solução e que, dispondo de tempo suficiente, pode encontrar a solução ótima global. De forma simplificada, estes modelos funcionam explorando o espaço de soluções definido pelas variáveis de decisão. Contudo, para que o solver possa melhorar iterativamente uma solução, tem primeiro de encontrar uma solução viável inicial, o que pode ser particularmente difícil em problemas de grande dimensão e elevada complexidade.
Num problema de escalonamento, o número de variáveis de decisão que define a dimensão do espaço de soluções cresce exponencialmente com o número de ordens.
No nosso caso, com 100 ordens, o modelo tinha cerca de 30.000 variáveis de decisão. Se o número de ordens duplicasse para 200, o modelo passaria a ter aproximadamente 110.000 variáveis.
Our AI-generated summary
Our AI-generated summary
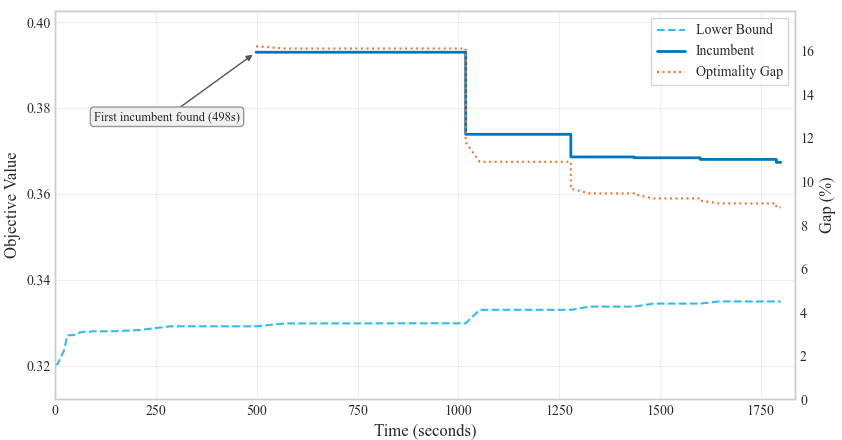
Ainda assim, a primeira abordagem consistiu em aplicar otimização exata clássica, recorrendo ao solver Gurobi. Tal como antecipado, rapidamente se confirmou a principal limitação: a dificuldade em encontrar uma solução inicial viável. Cerca de 30% do tempo total de execução era consumido apenas na procura da primeira solução.
Inverter a estratégia: pesquisa global antes de otimização local
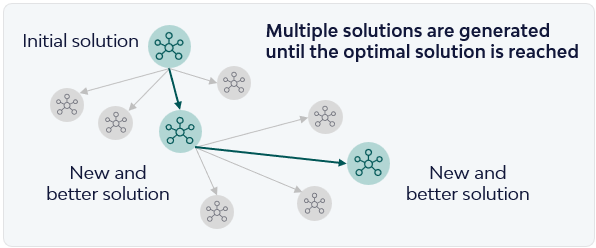
Perante este bloqueio, tornou-se necessário repensar a abordagem. A estratégia foi invertida: primeiro realizar uma pesquisa global rápida para encontrar uma solução inicial viável, ainda que subótima, e, posteriormente, aplicar otimização local com um solver MILP para melhorar a qualidade da solução.
A obtenção rápida de uma solução inicial poderia ser alcançada através de metaheurísticas, amplamente estudadas na literatura e particularmente eficazes na geração de boas soluções em horizontes temporais reduzidos, ainda que sem garantia de otimalidade. Optou-se por uma das metaheurísticas mais utilizadas: o Algoritmo Genético (GA).
Conceber um warm start evolutivo
Um Algoritmo Genético é um algoritmo evolutivo inspirado na dinâmica da seleção natural. Parte de uma população de soluções candidatas — designadas cromossomas — que evoluem ao longo de gerações sucessivas. Neste caso, cada cromossoma codificava uma sequência semanal completa de ordens nas 6 linhas de produção. Em cada geração, os melhores indivíduos eram selecionados, combinados através de operadores de crossover e sujeitos a mutações que introduziam variação. O objetivo era maximizar a função de fitness, que refletia a função objetivo do modelo MILP.
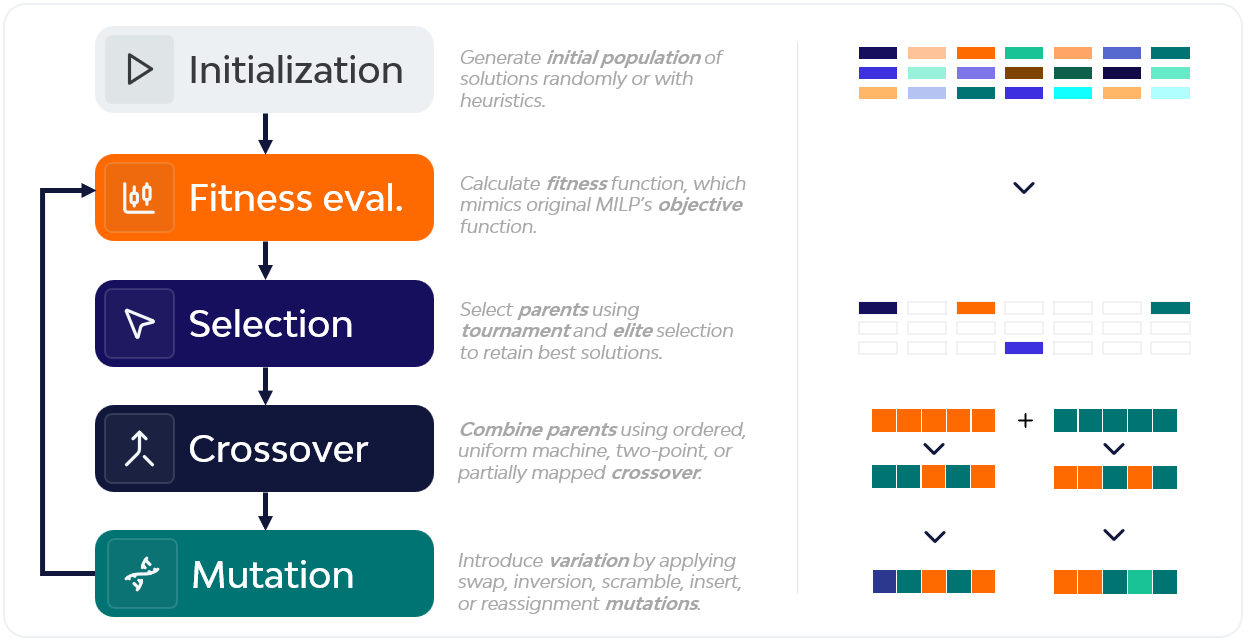
Para além da estrutura tradicional do GA, foi incorporado um pequeno componente de reforço baseado em Q-learning, com o objetivo de selecionar operadores de crossover e mutação de forma mais inteligente, em vez de aleatória. Os parâmetros do GA foram ainda ajustados através do método de Taguchi, reduzindo significativamente o número de combinações de parâmetros a testar.
Refinar a solução
O Algoritmo Genético conseguiu gerar rapidamente uma solução viável, ainda que distante do ótimo.
A etapa seguinte consistiu em utilizar essa solução como warm start para um modelo MILP, com o intuito de melhorar a sua qualidade. Foram exploradas duas estratégias:
- Utilizar a solução gerada pelo GA como ponto de partida para um solver de otimização exata clássico;
- Utilizar a solução do GA como ponto de partida para uma heurística Fix-and-Optimize (F&O).
A heurística Fix-and-Optimize funciona fixando iterativamente uma percentagem das variáveis de decisão e permitindo que o solver reotimize as variáveis restantes, explorando uma vizinhança local em torno da melhor solução corrente.
Como funciona o pipeline híbrido
Se tiver curiosidade em perceber como esta abordagem funciona de ponta a ponta, segue abaixo uma versão simplificada em pseudo-código do pipeline:
1: Start timer
2: population ← InitializePopulation(problem data)
3: EvaluateFitness(population)
4: x* ← BestIndividual(population)
5: while elapsed_time < ga_time do
6: parents ← SelectParents(population)
7: offspring ← ApplyCrossoverAndMutation(parents, Q-learning, GA parameters)
8: EvaluateFitness(offspring)
9: population ← FormNewPopulation(population, offspring)
10: x* ← UpdateBest(population, x*)
11: end while
12: remaining_time ← total_time − elapsed_time
13: if solving_mode = EXACT then
14: x* ← SolveFullMILP(problem data, warm_start = x*, time_limit = remaining_time)
15: else
16: for each stage in F&O_stages do
17: for iter = 1 to stage.iterations do
18: FixSubsetOfJobs(stage.fix_percentage, based_on = x*)
19: candidate ← SolveSubMIP(problem data, warm_start = x*, time_limit = stage.time)
20: if Objective(candidate) < Objective(x*) then x* ← candidate
21: end for
22: end for
23: end if
24: return x* Foi ainda analisada uma decisão crítica: quanto tempo deveria o Algoritmo Genético executar para gerar a solução inicial, considerando um limite total de 30 minutos de tempo de computação.
Foram testadas seis configurações distintas, permitindo que o GA executasse durante 30 segundos, 1 minuto, 2 minutos, 5 minutos, 10 minutos e 15 minutos, utilizando o tempo restante para Fix-and-Optimize ou para otimização exata.
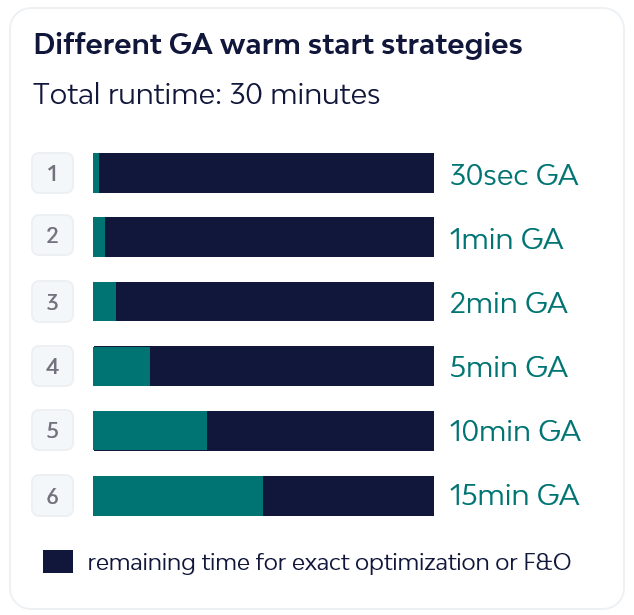
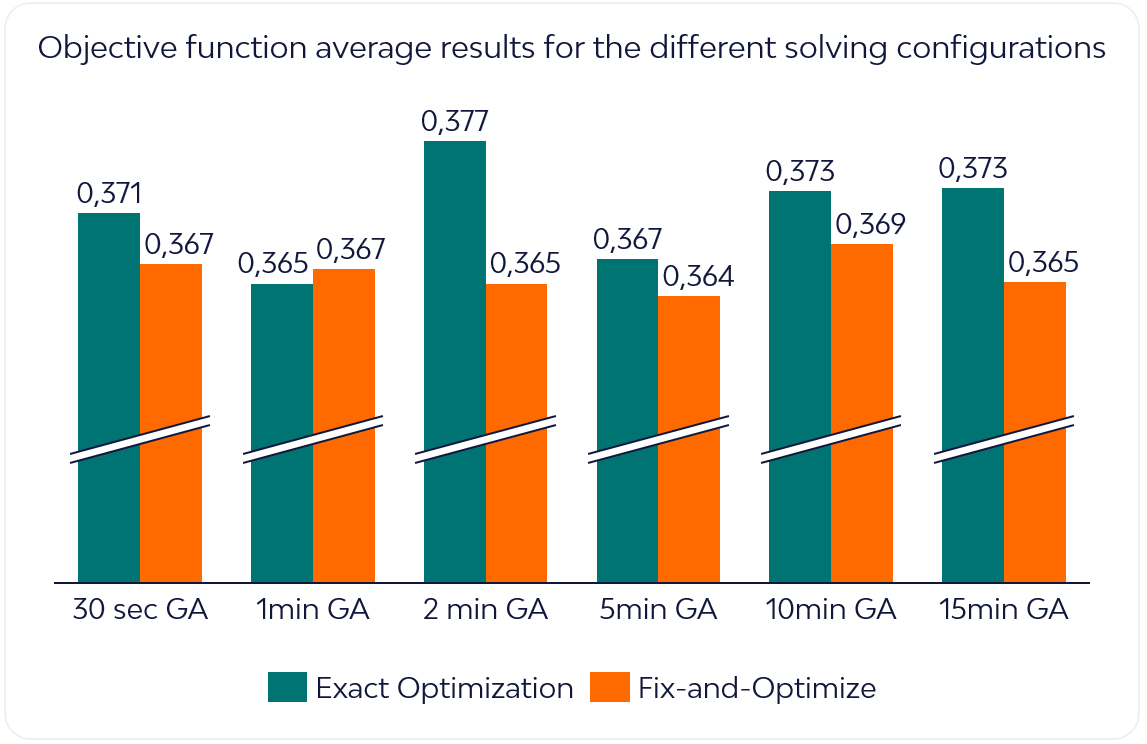
Realizou-se um conjunto de testes para avaliar o desempenho das duas abordagens — GA seguido de otimização exata ou GA seguido de Fix-and-Optimize — para as diferentes durações do warm start. Tratando-se de um problema de minimização, valores mais baixos da função objetivo correspondiam a melhores soluções.
O que efetivamente funcionou (e porquê)
Os resultados médios demonstraram que a combinação Fix-and-Optimize com Algoritmo Genético superou a abordagem de otimização exata com warm start do GA na maioria das configurações testadas.
A abordagem Fix-and-Optimize atingiu os melhores resultados com um warm start de 5 minutos de GA. Intuitivamente, períodos de warm start demasiado curtos forneciam pouca orientação estrutural à heurística F&O, conduzindo a soluções de menor qualidade. Por outro lado, períodos demasiado longos produziam soluções iniciais melhores, mas deixavam tempo insuficiente para o refinamento MILP. Entre estes extremos existe um ponto ótimo de equilíbrio.
Em síntese, para problemas combinatórios complexos, como o escalonamento da produção, a combinação das forças das metaheurísticas com solvers MILP pode conduzir a soluções superiores, sobretudo quando existem limites rígidos de tempo de resolução. Em particular, quando o espaço de soluções é tão vasto que o solver tem dificuldade em encontrar uma primeira solução viável, esta abordagem híbrida revela-se especialmente pertinente. Neste caso, as metaheurísticas não substituíram o solver MILP, apenas tornaram-no operacional à escala exigida pelo problema.